r-na druhou (R2)
měří podíl variace ve vaší závislé proměnné vysvětlené všemi vašimi nezávislými proměnnými v modelu. Předpokládá, že každá nezávislá proměnná v modelu pomáhá vysvětlit změnu závislé proměnné., Ve skutečnosti některé nezávislé proměnné (prediktory) nepomáhají vysvětlit závislou (cílovou) proměnnou. Jinými slovy, některé proměnné nepřispívají k předpovídání cílové proměnné.
matematicky se R-na druhou vypočítá vydělením součtu čtverců reziduí (SSres) celkovým součtem čtverců (SStot) a poté je odečte od 1. V tomto případě sstot měří celkovou odchylku. Opatření SSreg vysvětlovala rozdíly a opatření SSres nevysvětlitelná variace.,
as SSres + SSreg = SStot, R2 = vysvětlená variace / celková variace
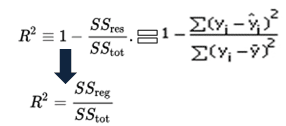
r-čtvercová rovnice
R-na druhou se také nazývá koeficient stanovení. Leží mezi 0% a 100%. Hodnota R na druhou 100% znamená, že model vysvětluje všechny variace cílové proměnné. A hodnota 0% měří nulovou prediktivní sílu modelu. Vyšší hodnota R-na druhou, lepší model.
upravený R-na druhou
měří podíl variací vysvětlených pouze těmi nezávislými proměnnými, které skutečně pomáhají při vysvětlování závislé proměnné., Trestá vás za přidání nezávislé proměnné, která nepomůže při předpovídání závislé proměnné.
upravený R-na druhou lze vypočítat matematicky z hlediska součtu čtverců. Jediný rozdíl mezi R-čtvercem a upravenou R-čtvercovou rovnicí je stupeň volnosti.
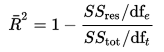
upravená R-čtvercová rovnice
ve výše uvedené rovnici je DFT stupně volnosti n-1 odhadu populační variance závislé proměnné a dfe je stupně volnosti n – p-1 odhadu rozptylu základní populace.,
upravená hodnota R-na druhou lze vypočítat na základě hodnoty R-na druhou, počtu nezávislých proměnných (prediktorů), celkové velikosti vzorku.

Adjusted R-Squared Rovnice 2
Rozdíl mezi R-square a Adjusted R-square
- po Každém přidání nezávislé proměnné do modelu, R-squared zvyšuje, i když nezávislé proměnné je nevýznamné. Nikdy to neklesne. Zatímco upravená R-na druhou se zvyšuje pouze tehdy, je-li nezávislá proměnná významná a ovlivňuje závislou proměnnou.,
- Adjusted r-squared může být negativní, když je r na druhou se blíží nule.
- upravená hodnota R-na druhou je vždy menší nebo rovna hodnotě R-na druhou.
V následující tabulce je nastavený r-na druhou maximální, když jsme zahrnuli dvě proměnné. Klesá, když je přidána třetí proměnná. Zatímco R-na druhou se zvyšuje, když jsme zahrnuli třetí proměnnou. To znamená, že třetí proměnná je pro model nevýznamná.
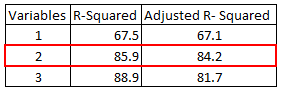
R-Squared vs. Upravené R-Kvadrát,
upravený R-čtverec by měl být použit k porovnání modelů s různými počty nezávislých proměnných. Upravený R-čtverec by měl být použit při výběru důležitých prediktorů (nezávislých proměnných) pro regresní model.
R: Vypočítejte R-na druhou a upravený R-na druhou
Předpokládejme, že máte skutečné a předpovídané závislé proměnné hodnoty. Ve skriptu níže jsme vytvořili vzorek těchto hodnot. V tomto příkladu y odkazuje na pozorovanou závislou proměnnou a yhat odkazuje na předpovězenou závislou proměnnou.,
Konečný výsledek: R-na druhou = 0.6410828
předpokládejme, že v tomto případě máte tři nezávislé proměnné.
n = 10
p = 3
adj.r.na druhou = 1 – (1 – R na druhou) * ((n – 1)/(n-p-1))
print(adj.r.na druhou)
V tomto případě, se upraví hodnota spolehlivosti r je 0.4616242 za předpokladu, že máme 3 prediktory a 10 pozorování.